1.单词的向量化表示
一般来讲,词向量主要有两种形式,分别是稀疏向量和密集向量。
所谓稀疏向量,又称为one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词典的大小N,向量的分量只有一个1,其他全为0,1的位置对应该词在词典中的索引。
至于密集向量,又称distributed representation,即分布式表示。最早由Hinton提出,可以克服one-hot representation的上述缺点,基本思路是通过训练将每个词映射成一个固定长度的短向量,所有这些向量就构成一个词向量空间,每一个向量可视为该空间上的一个点。
2.word2vec的语言模型
所谓的语言模型,就是指对自然语言进行假设和建模,使得能够用计算机能够理解的方式来表达自然语言。word2vec采用的是n元语法模型(n-gram model),即假设一个词只与周围n个词有关,而与文本中的其他词无关。
CBOW模型能够根据输入周围n-1个词来预测出这个词本身,而skip-gram模型能够根据词本身来预测周围有哪些词。也就是说,CBOW模型的输入是某个词A周围的n个单词的词向量之和,输出是词A本身的词向量;而skip-gram模型的输入是词A本身,输出是词A周围的n个单词的词向量。
3.基于Hierarchical Softmax的模型
理论上说,无论是CBOW模型还是skip-gram模型,其具体的实现都可以用神经网络来完成。问题在于,这样做的计算量太大了。我们可以简略估计一下。首先定义一些变量的含义[3]:
(1) n : 一个词的上下文包含的词数,与n-gram中n的含义相同 (2) m : 词向量的长度,通常在10~100 (3) h : 隐藏层的规模,一般在100量级 (4) N :词典的规模,通常在1W~10W (5) T : 训练文本中单词个数以CBOW为例,输入层为n-1个单词的词向量,长度为m(n-1),隐藏层的规模为h,输出层的规模为N。那么前向的时间复杂度就是o(m(n-1)h+hN) = o(hN) 这还是处理一个词所需要的复杂度。如果要处理所有文本,则需要o(hNT)的时间复杂度。这个是不可接受的。同时我们也注意到,o(hNT)之中,h和T的值相对固定,想要对其进行优化,主要还是应该从N入手。而输出层的规模之所以为N,是因为这个神经网络要完成的是N选1的任务。那么可不可以减小N的值呢?答案是可以的。解决的思路就是将一次分类分解为多次分类,这也是Hierarchical Softmax的核心思想。举个栗子,有[1,2,3,4,5,6,7,8]这8个分类,想要判断词A属于哪个分类,我们可以一步步来,首先判断A是属于[1,2,3,4]还是属于[5,6,7,8]。如果判断出属于[1,2,3,4],那么就进一步分析是属于[1,2]还是[3,4],以此类推,如图中所示的那样。这样一来,就把单个词的时间复杂度从o(h*N)降为o(h*logN),更重要的减少了内存的开销。
4.word2vec的大概流程
至此,word2vec中的主要组件都大概提到过一遍,现在应该把它们串起来,大概了解一下word2vec的运行流程。
(1) 分词 / 词干提取和词形还原。 中文和英文的nlp各有各的难点,中文的难点在于需要进行分词,将一个个句子分解成一个单词数组。而英文虽然不需要分词,但是要处理各种各样的时态,所以要进行词干提取和词形还原。
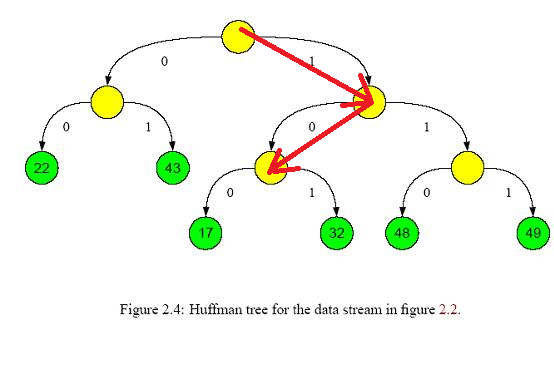
(2) 构造词典,统计词频。这一步需要遍历一遍所有文本,找出所有出现过的词,并统计各词的出现频率。 (3) 构造树形结构。依照出现概率构造Huffman树。如果是完全二叉树,则简单很多,后面会仔细解释。需要注意的是,所有分类都应该处于叶节点,像下图显示的那样[4]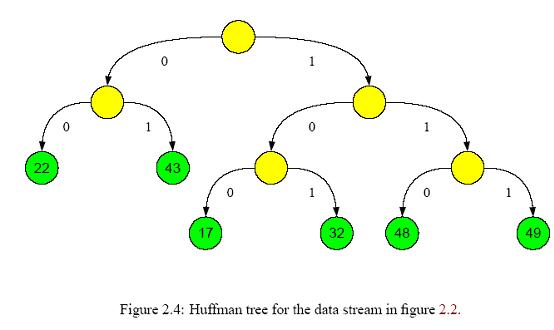
(4)生成节点所在的二进制码。拿上图举例,22对应的二进制码为00,而17对应的是100。也就是说,这个二进制码反映了节点在树中的位置,就像门牌号一样,能按照编码从根节点一步步找到对应的叶节点。
(5) 初始化各非叶节点的中间向量和叶节点中的词向量。树中的各个节点,都存储着一个长为m的向量,但叶节点和非叶结点中的向量的含义不同。叶节点中存储的是各词的词向量,是作为神经网络的输入的。而非叶结点中存储的是中间向量,对应于神经网络中隐含层的参数,与输入一起决定分类结果。 (6) 训练中间向量和词向量。对于CBOW模型,首先将词A附近的n-1个词的词向量相加作为系统的输入,并且按照词A在步骤4中生成的二进制码,一步步的进行分类并按照分类结果训练中间向量和词向量。举个栗子,对于绿17节点,我们已经知道其二进制码是100。那么在第一个中间节点应该将对应的输入分类到右边。如果分类到左边,则表明分类错误,需要对向量进行修正。第二个,第三个节点也是这样,以此类推,直到达到叶节点。因此对于单个单词来说,最多只会改动其路径上的节点的中间向量,而不会改动其他节点。